Aperi’CTF 2019 - Pick up the phone 2
Challenge details
| Event | Challenge | Category | Points | Solves |
|---|---|---|---|---|
| Aperi’CTF 2019 | Pick up the phone 2 | Forensic | 100 | 8 |
We’re given a call.pcap PCAP file.
Task description:
Following the President’s attack on our company’s sales manager, our engineering team designed a new authentication system based on a single-use token (HOTP).
In order to retrieve this token, users can call a dedicated voice service and retrieve a new token on their LCD screen.
Despite the security guidelines, some users tend to create a token list by calling the voice service several times in order to use them later…
However, our VoIP communication system appears to have been tapped and one of our CEO’s unused tokens leaked.
Investigate and find the leaked authentication token to allow our technicians to revoke it.
TL;DR
Replay RTP Stream with Wireshark on a virtual audio device, decode the DTMF sequences.
PCAP analysis
Since, we’re given a PCAP file, let’s enumerate the protocols using tshark:
tshark -r files/call.pcap -T fields -e frame.protocols | sort | uniq | grep -vP "((tcp)|(udp)|(data))$"
eth:ethertype:ip:udp:rtp
eth:ethertype:ip:udp:sip
eth:ethertype:ip:udp:sip:sdp
Ok, this capture seems to contain a SIP/RTP conversation, that’s perfect! Let’s analyze it using Wireshark!
First, let’s filter the packets using the rtp filter:
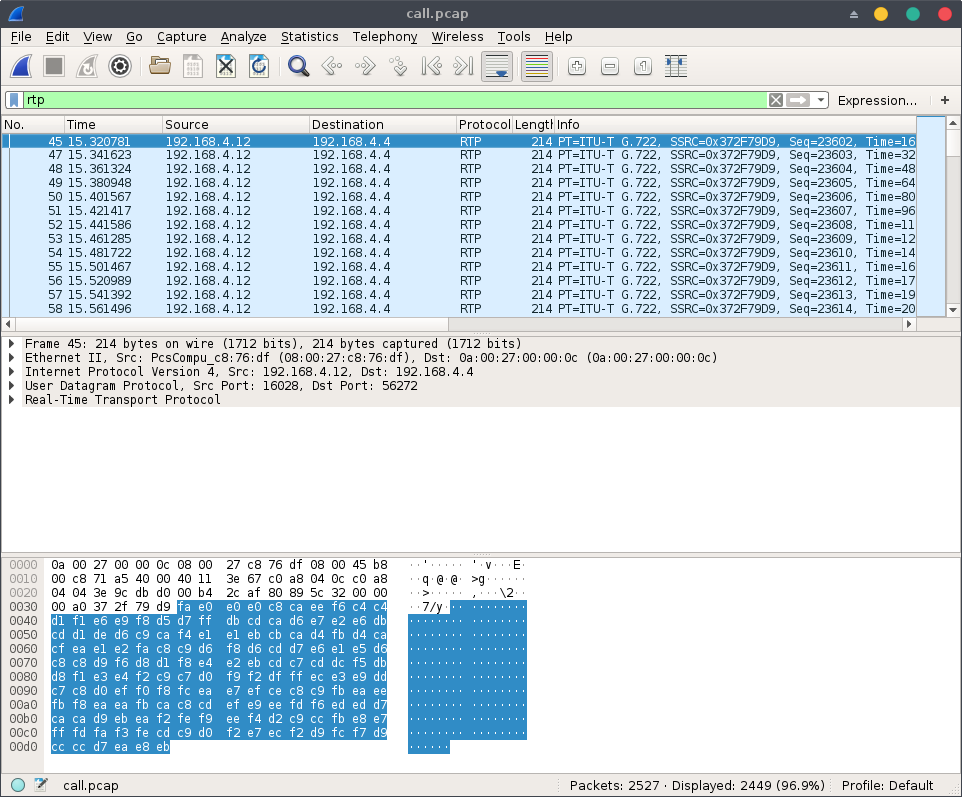
Using Wireshark, there’s an interesting feature when we’re anaylzing an RTP stream that allows us to replay voice session under Telephony > RTP > RTP Streams:
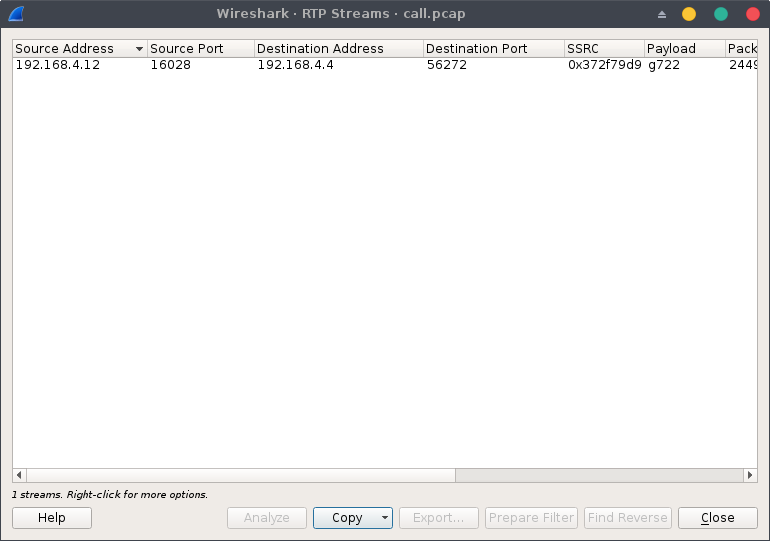
There is only one RTP stream containing a G.722 encoded communication, we can replay it using the RTP player under Analyze > Play Streams:
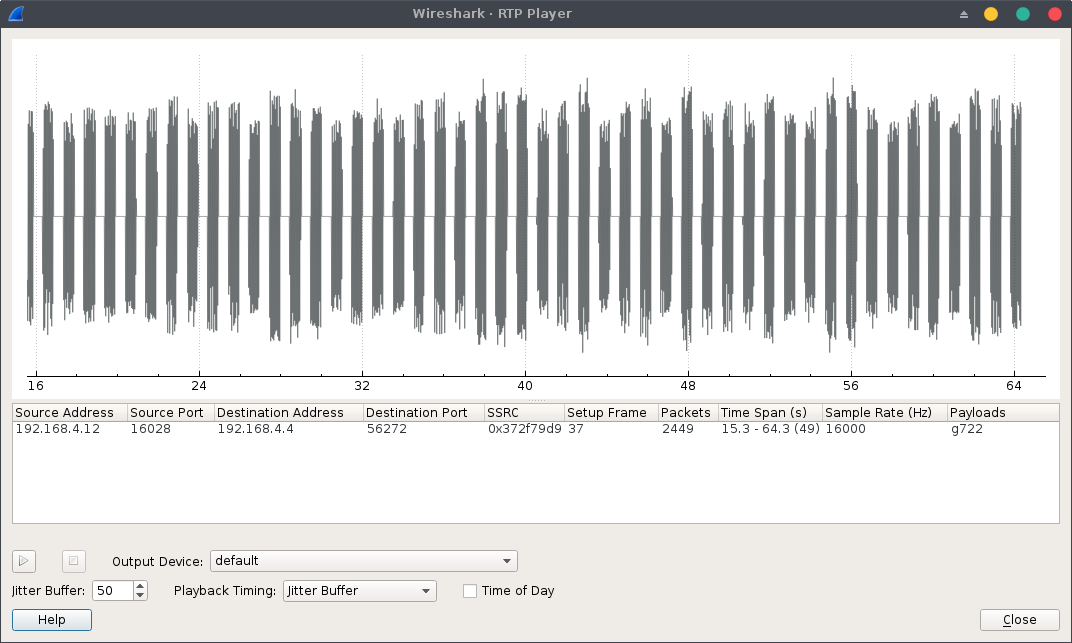
Listening to the RTP stream, we can notice that there’s no voice at all, only a beep-sequence which after few web searches appears to be dual-tone multi-frequency signaling sequence.
To decode the DTMF sequence, we can use our auditory abilities to recognize and decode the touch tones or use decoders.
Since the payload’s 50 seconds long, we’ll focus on using a decoder here.
Exporting DTMF sequences
Using a Linux environment, we can create a virtual audio device to replay the RTP stream and record it using Audacity.
Firstly, we need to load the module-null-sink module on PulseAudio in order to create an audio sink device:
pactl load-module module-null-sink sink_name=virtual-sound-device
Now using the pavucontrol GUI interface, we can check that our virtual device has been created:
If our audio sink device is listed, we can now run Audacity and start a recording session on the default line using a mono channel:
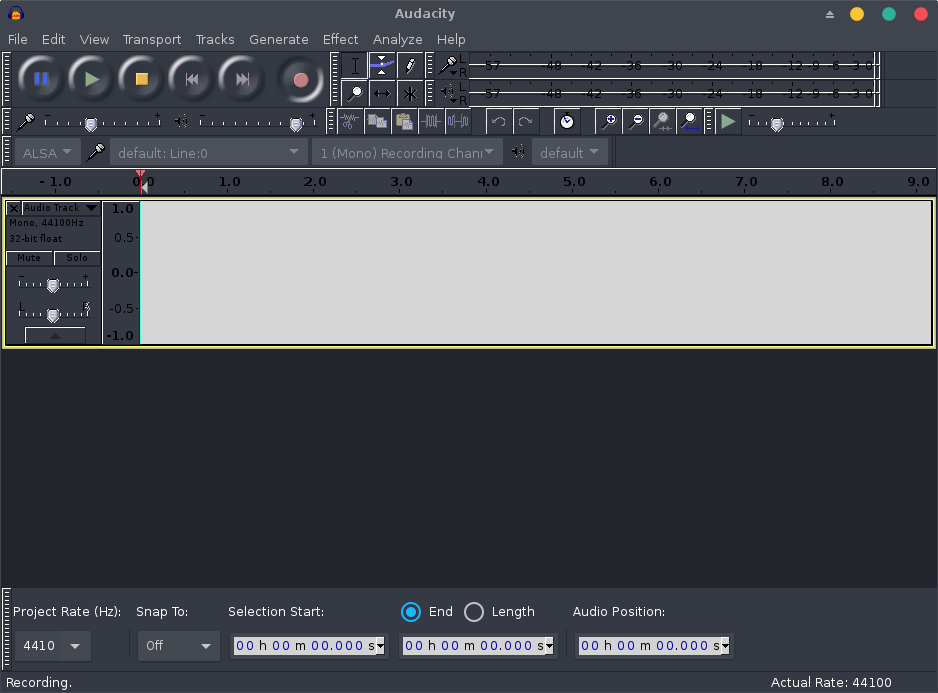
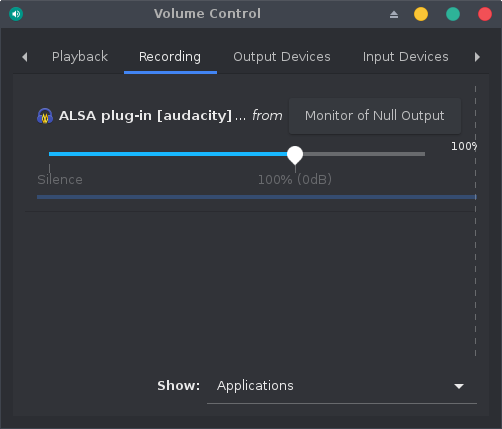
On the pavucontrol, let’s just switch the recording device associated to Audacity from Built-in Audio Analog Stereo to Monitor of Null Output:
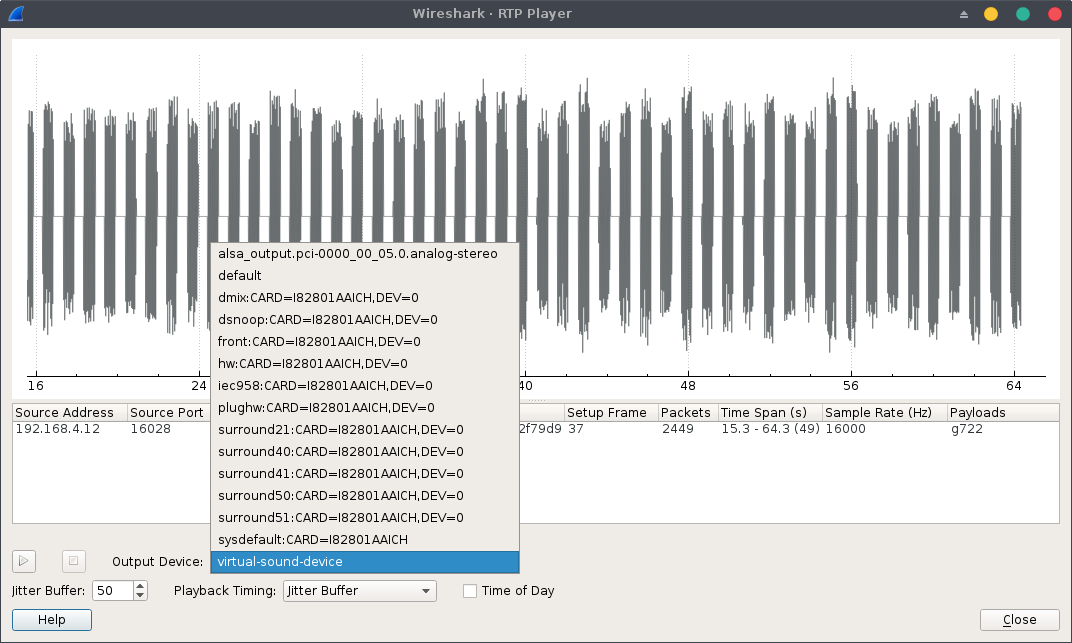
We can now replay the RTP stream on Wireshark using the virtual-sound-device and see the output directly on Audacity:
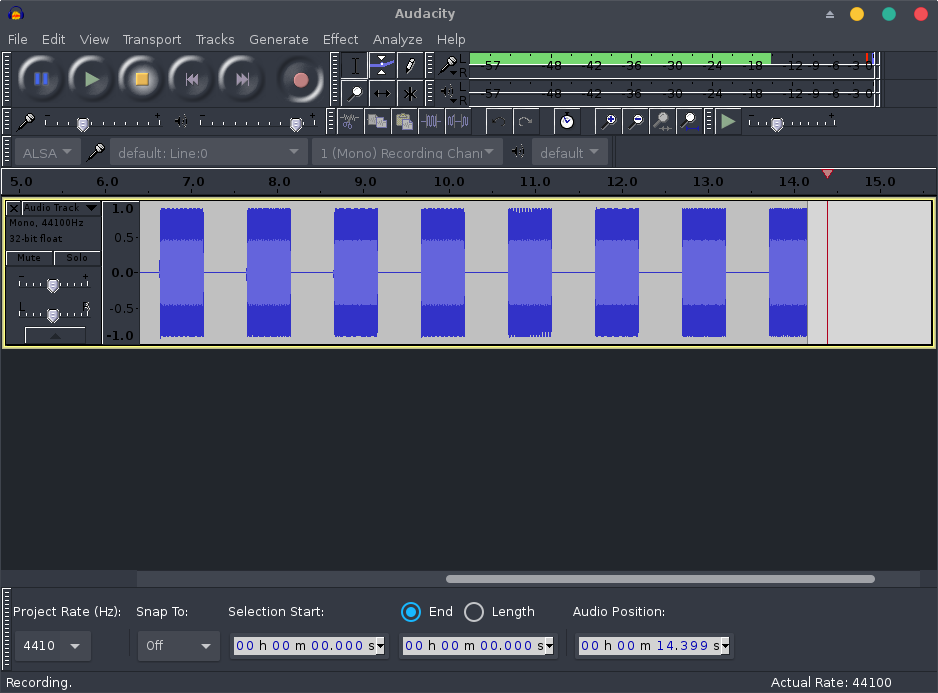
When the entire conversation is recorded, we can stop the capture and export the audio to a PCM 8KHz WAV file!
Decoding DTMF sequences
Now, we just need to split the entire conversation in multiple samples with a maximum of 10 seconds and decode them using dialabc:
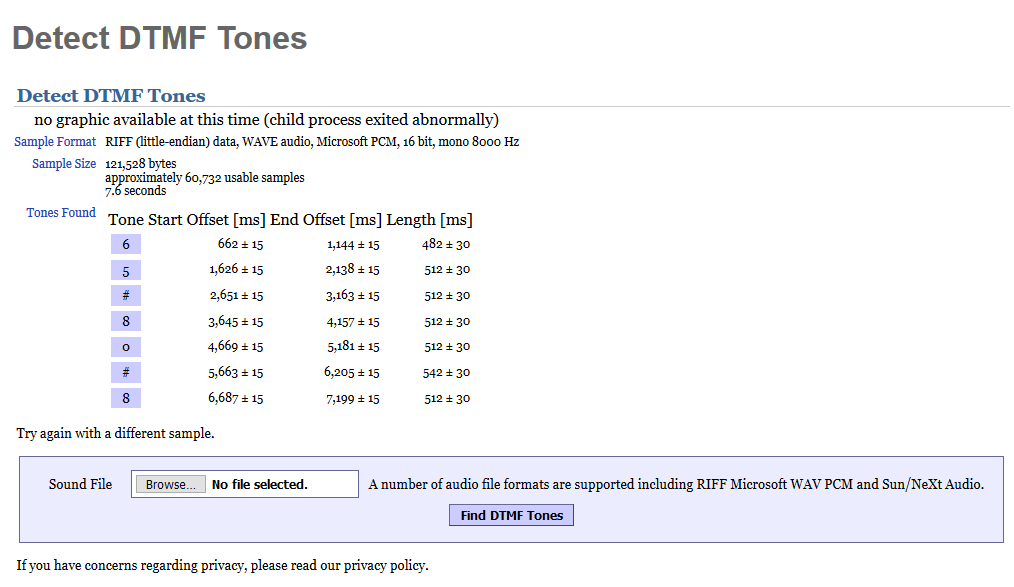
Another faster and neat way (credits to Yann BREUT from Airbus CyberSecurity for this solution) is to decode the DTMF sequences using multimon-ng:
multimon-ng -t wav -a dtmf dtmf.wav
We should obtain the following result:
65#80#82#75#123#80#72#114#51#52#107#49#110#54#125
We recognize the use of a dialpad which only allows the use of the following charset:
123456789*0#
We can assume that the message is composed of ASCII decimal values separated by #. Let’s decode it using Python:
message = '65#80#82#75#123#80#72#114#51#52#107#49#110#54#125'
decoded = ''.join(map(chr, map(int, message.split('#'))))
print(decoded)
The final flag is APRK{PHr34k1n6!}
Happy Hacking!