Challenge details
| Event | Challenge | Category | Points | Solves |
|---|---|---|---|---|
| TamuCTF 2019 | ReadingRainbow - 3_Data | Forensic | 100 | 122 |
Download: capture.pcap - md5: e36ff23c6995e3595035982cced6c6a9
Description
- What compression encoding was used for the data?
- What is the name and type of the decompressed file? (Format: NAME.TYPE e.g. tamuctf.txt)
Difficulty: medium-hard
capture.pcap - md5: e36ff23c6995e3595035982cced6c6a9
TL;DR
I extracted ICMP, HTTP and DNS data with wireshark and tshark than I scripted with python and finally identified a gzip file.
Methology
Before answering the questions, it will be necessary to find a way to recover the original file. We know that the attacker used HTTP, DNS and ICMP protocols between IP 192.168.11.7 (attacker) and 192.168.11.4 (webserver) to extract his file. We will, therefore, use the following filter and save only the displayed packets to make a lightened PCAP file:
ip.src == 192.168.11.4 && ip.dst == 192.168.11.7 && (http || dns || icmp)
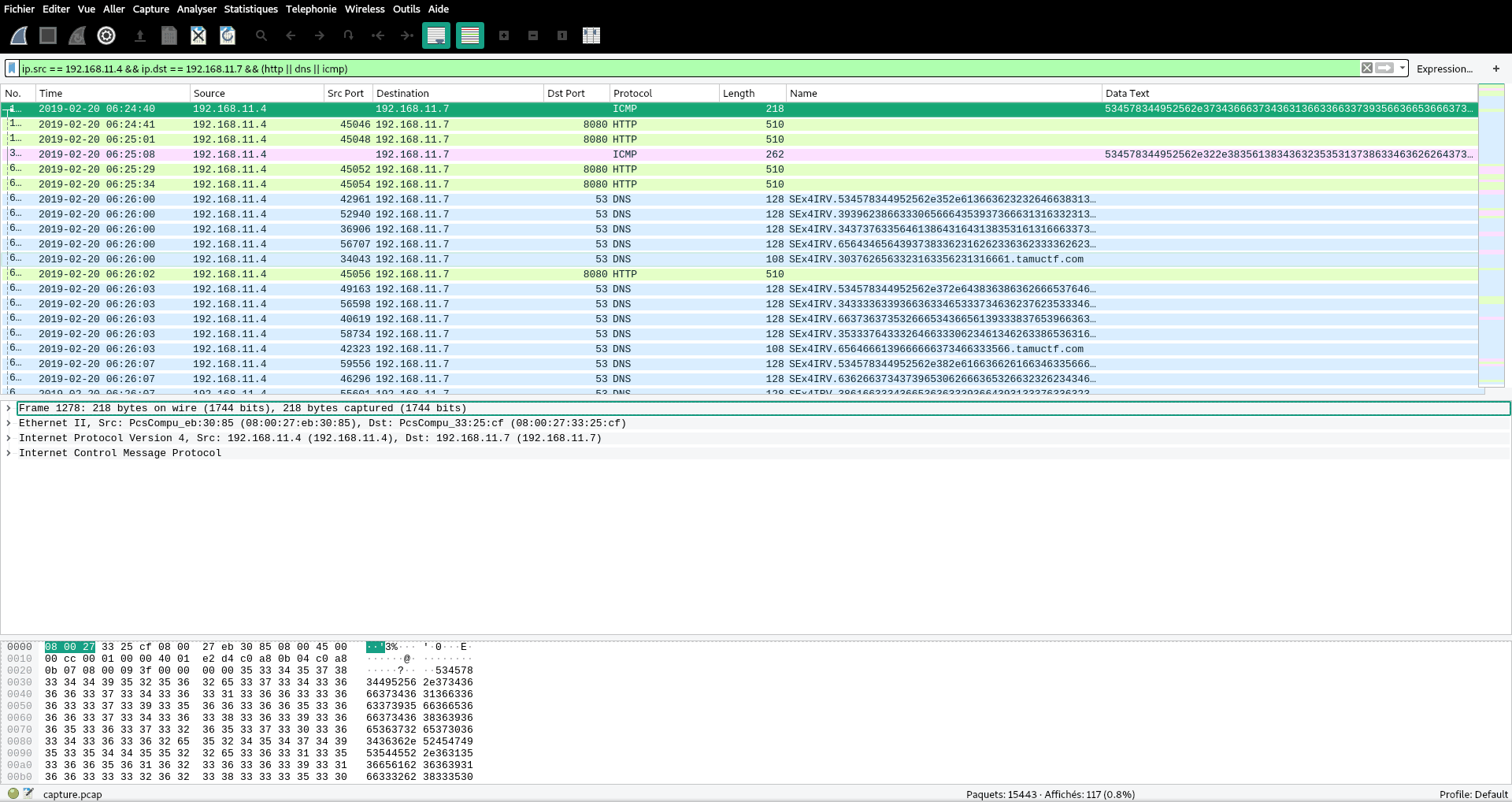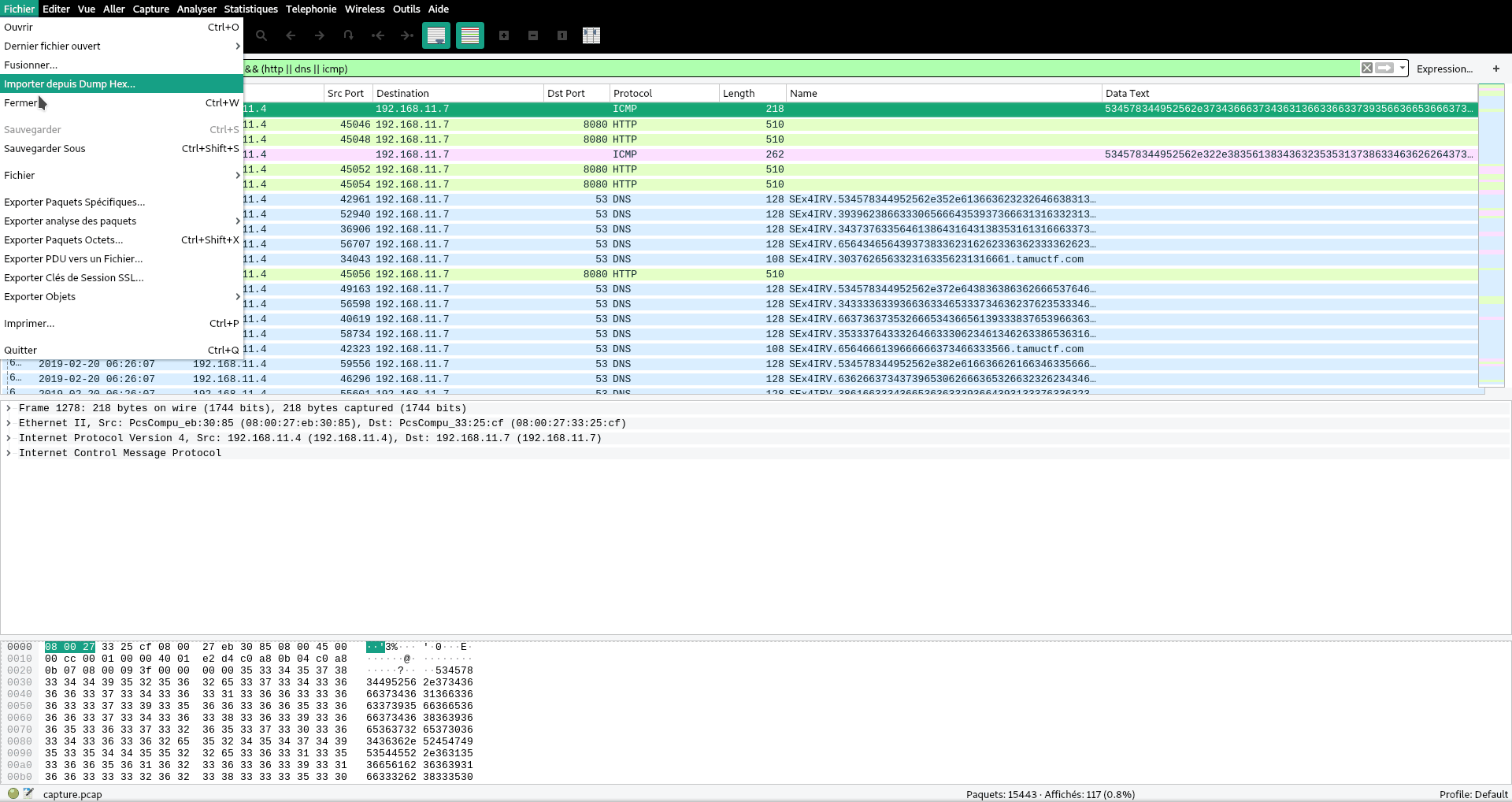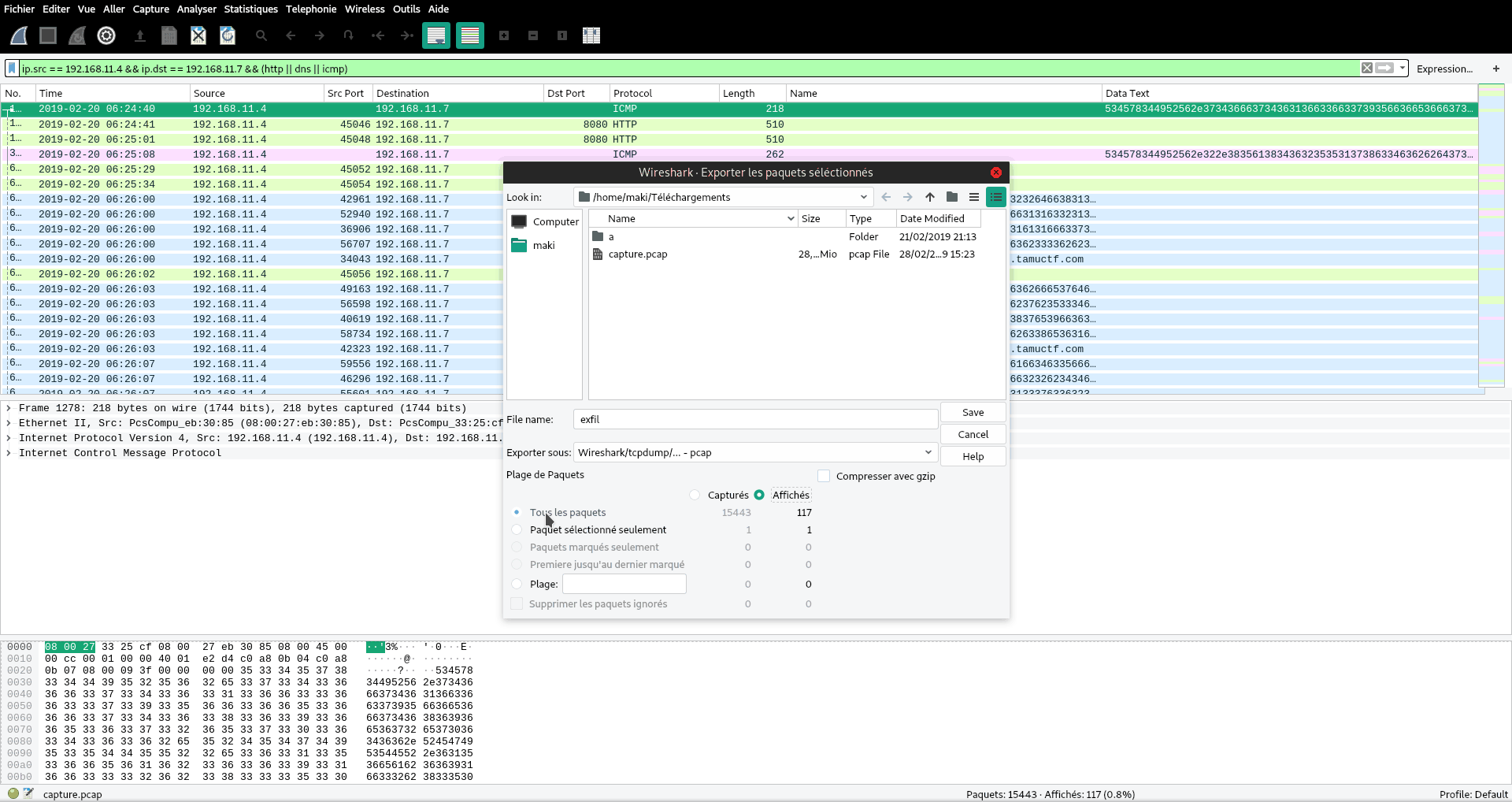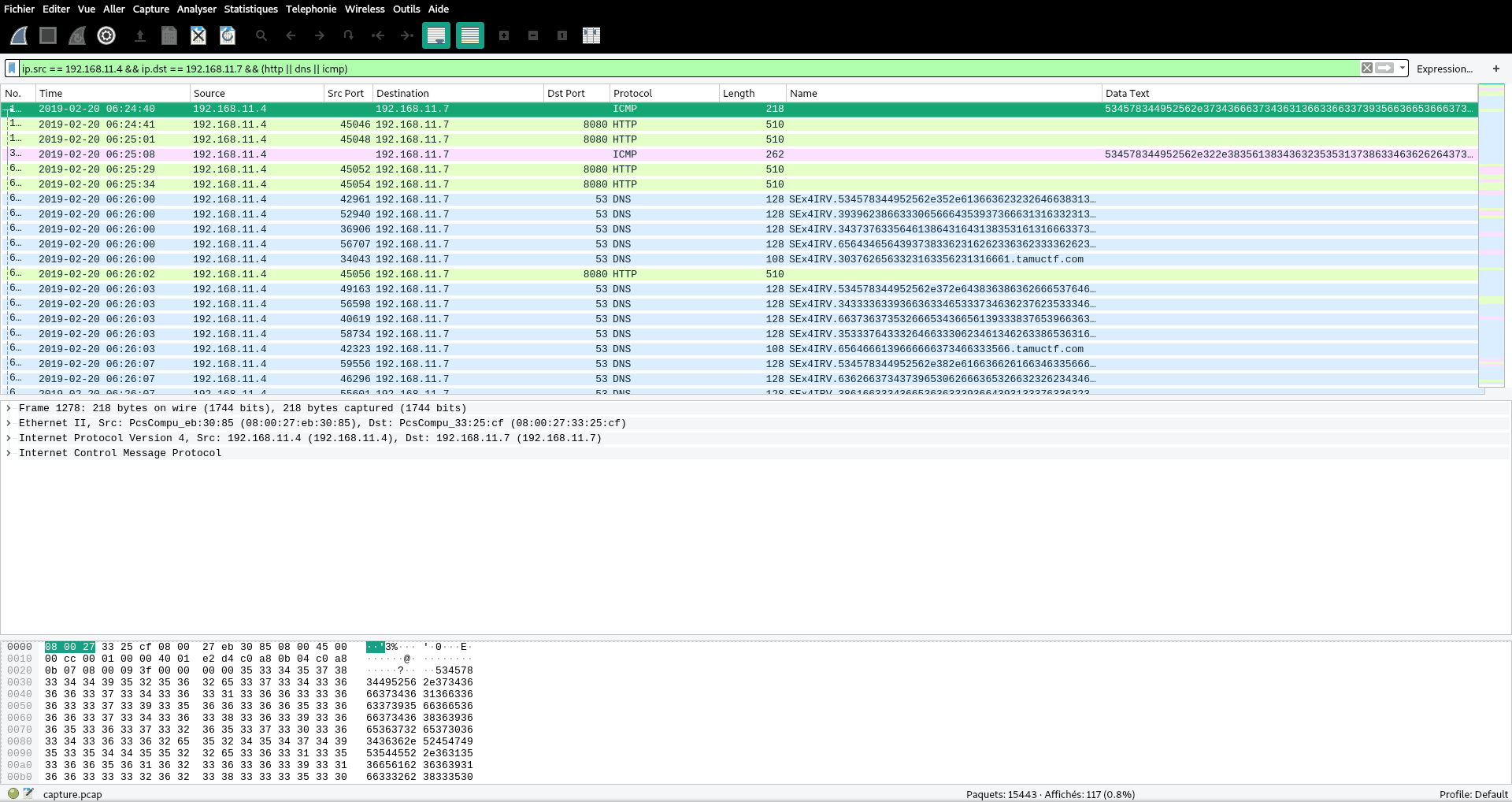
Fig 1: Lightweight PCAP
We go from 15k packets to 117, it’s still more pleasant to analyze.
Get data from ICMP
ICMP data is sent in hexadecimal when decoding on the fly with xxd piped to tshark there is no more line break and the data becomes difficult to analyze. For that, there is sed which will add more returns to the line:
▶ tshark -r exfil.pcap -Y "icmp" -Tfields -e "data.text" | xxd -r -p | sed 's/SEx4IRV/\nSEx4IRV/g'
SEx4IRV.746f74616c6c795f6e6f7468696e672e706466.REGISTER.6156eab6691f32b8350c45b3fc4aadc1
SEx4IRV.2.85a846255178c4cbbd77ee999d7b7736892afaa392cf6ae7ccf9ee39f79efb9c3367325a767c1c7db414c0d4dadc4c78b0b5
SEx4IRV.12.2bb53aaf40c5354868c984db4df8b209379f172b26dcbc5f6e99f04a130ef3e234f944e875a64f746d26fc920977987079ee
[...]
▶ tshark -r exfil.pcap -Y "icmp" -Tfields -e "data.text" | xxd -r -p | sed 's/SEx4IRV/\nSEx4IRV/g' > clear_icmp
These are the ICMP data extracted from a file.
Get data from HTTP
HTTP data are sent as POST data:
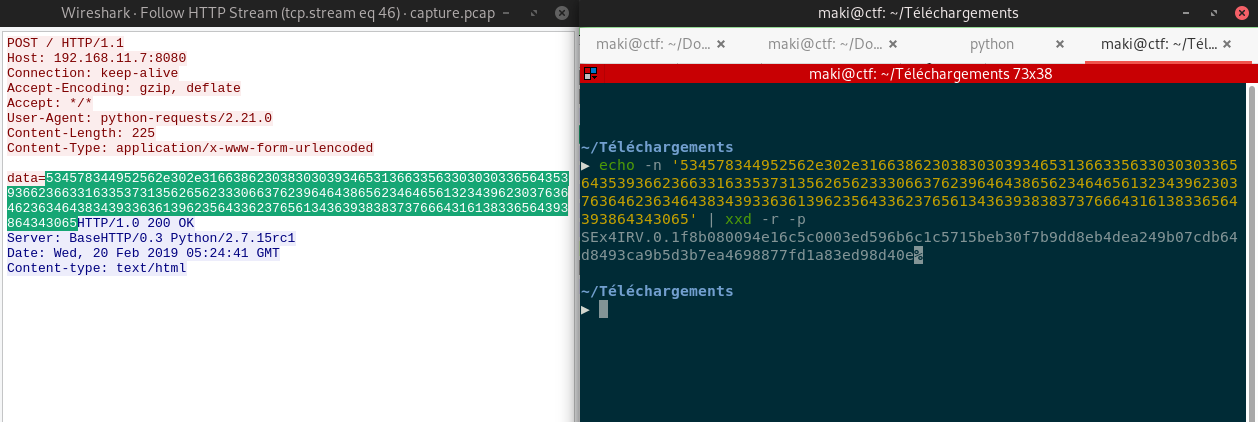
Fig 2: HTTP hex encoded data
Same process as for ICMP:
▶ tshark -r exfil.pcap -Y "http" -Tfields -e urlencoded-form.value | xxd -r -p | sed 's/SEx4IRV/\nSEx4IRV/g'
SEx4IRV.0.1f8b080094e16c5c0003ed596b6c1c5715beb30f7b9dd8eb4dea249b07cdb64d8493ca9b5d3b7ea4698877fd1a83ed98d40e
SEx4IRV.1.01ea4cd7deb1bdb00f6b77b6d8018125a755b7a94390a0ca1f50a5a20a103f5ca844040236b82a25bf1250451005b9555339
SEx4IRV.3.3960e6981a034d81000a36ed6f6a0ab6049a5b5a5120d818686c41bec047ec17a56c468ba47d3ea44512d931adfc50dcadfc
▶ tshark -r exfil.pcap -Y "http" -Tfields -e urlencoded-form.value | xxd -r -p | sed 's/SEx4IRV/\nSEx4IRV/g' > clear_http
Get data from DNS
The functioning of the DNS is a bit more different, because each request will be encoded in another.
▶ tshark -r exfil.pcap -Y "dns" -Tfields -e dns.qry.name | cut -d'.' -f2 | xxd -r -p | sed 's/SEx4IRV/\nSEx4IRV/g'
SEx4IRV.5.a6cb22df81782e99b8f30efd5976f11c219f61477c5da8d1d1851a1fc79f60ed4ed9783b1bb3cb33bb3cd307bec21c5b11fa
SEx4IRV.7.d868cbfe7df168433c96cc4e374cb7b534b4ecf76752fe46ea9387e9f60c0c537d32df30b4a4bc8e61a4fcedfa9fff74f35f
SEx4IRV.8.af6baf4c5fb9f1cbf7479e0bfce2f22b44d7858af346e66396d9137c6238025db0a4cf2098419e36e0ff460bbca10cee2d83
▶ tshark -r exfil.pcap -Y "dns" -Tfields -e dns.qry.name | cut -d'.' -f2 | xxd -r -p | sed 's/SEx4IRV/\nSEx4IRV/g' > clear_dns
Ordering each request
All requests must be put back in the right order. This is how DET works:
- File ID
- Packet number
- Data
This query construction is not valid for the first (REGISTER) and last (DONE) requests. To put all this in order, python will do it for us. I will put all the lines in a dictionary with the packet number as the key:
f = open('clear_data')
a = f.read()
f.close()
final = ""
tmp = {}
for i in range(0,len(a)):
tmp[int(a[i].split('.')[1])] = a[i].split('.')[2]
for j in range(0,len(tmp)):
final = tmp[j]
g = open('result','wb')
g.write(final)
g.close()
Here is what we obtain:
▶ file result
result: ASCII text, with very long lines, with no line terminators
▶ cat result
1f8b080094e16c5c0003ed596b6c1c5715beb30f7b9dd8eb4dea249b07cdb64d8493ca9b5d3b7ea4698877fd1a83ed98d40e01ea4cd7deb1bdb00f6b7
[...]
▶ cat result | xxd -r -p > test
▶ file test
test: gzip compressed data, last modified: Wed Feb 20 05:11:48 2019, from Unix, original size 10240
Remember the first question of the challenge is the type of compression used:
Flag 1: gzip
Now, let’s uncompress the archive and got the original file:
▶ mv test test.gz
▶ gzip -d test.gz
▶ file test
test: POSIX tar archive (GNU)
▶ tar xvf test
stuff
▶ file stuff
stuff: ELF 64-bit LSB shared object, x86-64, version 1 (SYSV), dynamically linked, interpreter /lib64/ld-linux-x86-64.so.2, for GNU/Linux 3.2.0, BuildID[sha1]=e228bab316deed74b478d8f5bdef5d8c30bbd1b4, not stripped
And now, let’s validate the last flag:
Flag 2: stuff.elf
Flag
gzip
stuff.elf